Set di Caratteri HTML
Scopri i set di caratteri HTML — ASCII, ANSI, ISO-8859-1 e UTF-8 — e come dichiarare la codifica con il tag meta charset per visualizzare le pagine correttamente.
Un set di caratteri (o codifica dei caratteri) è la mappatura che indica al browser come convertire i byte grezzi di un file nelle lettere, cifre, segni di punteggiatura e simboli che vedi sullo schermo. Il browser deve conoscere il set di caratteri utilizzato da una pagina per visualizzarla correttamente.
UTF-8 è la codifica dei caratteri predefinita per HTML5. Non è sempre stato così. ASCII è arrivato per primo, e ISO-8859-1 era il set di caratteri predefinito da HTML 2.0 a HTML 4.01. Ciascuno di questi vecchi set poteva rappresentare solo un intervallo limitato di caratteri, il che causava problemi per il testo non in inglese. Quando UTF-8 arrivò insieme a HTML5 e XML, risolse la maggior parte di questi problemi coprendo praticamente tutti i sistemi di scrittura in un'unica codifica.
Questa pagina illustra i principali set di caratteri che potresti incontrare — ASCII, ANSI, ISO-8859-1 e Unicode/UTF-8 — e mostra come dichiarare la codifica sia nell'HTML moderno che in quello legacy.
Cosa va storto quando la codifica manca o non corrisponde
Se una pagina non dichiara la propria codifica, o ne dichiara una che non corrisponde a come il file è stato effettivamente salvato, il browser fa un'ipotesi — e spesso sbaglia. Il sintomo più comune è il mojibake: testo incomprensibile in cui lettere accentate, virgolette curve o emoji diventano sequenze come é o ’.
Oltre ad apparire rotto, un charset non dichiarato o non corrispondente può rappresentare un problema di sicurezza: alcuni attacchi si basano sul browser che interpreta i byte con una codifica diversa da quella intesa dall'autore (ad esempio, cross-site scripting basato su UTF-7). Dichiarare una singola codifica esplicita fin dall'inizio elimina questa ambiguità. La scelta moderna sicura è servire sempre i contenuti come UTF-8 e indicarlo chiaramente con <meta charset="UTF-8">.
ASCII
ASCII era il primo standard di codifica dei caratteri, noto anche come set di caratteri. È l'acronimo di American Standard Code for Information Interchange.
Per ogni carattere memorizzabile, ASCII ha definito un numero univoco per supportare l'alfabeto maiuscolo e minuscolo (a-z, A-Z), i numeri 0-9 e un insieme di caratteri speciali. È basato sull'alfabeto inglese e codifica 128 caratteri in un intero binario a 7 bit. Ad esempio, la lettera maiuscola A ha il codice 65 (binario 01000001), a è 97 e la cifra 0 è 48. Questo funziona perché tutte le informazioni informatiche sono in definitiva registrate come uni e zeri binari nell'elettronica.
Di seguito è riportata una tabella ASCII che mappa ciascun carattere al suo codice decimale, esadecimale e binario.
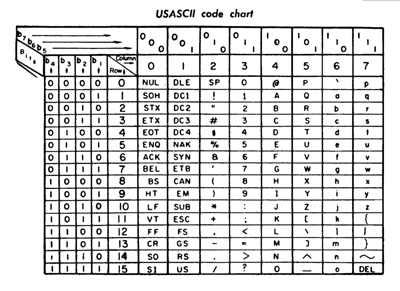
La principale limitazione di ASCII è che non include lettere non inglesi o caratteri accentati. È ancora in uso oggi, specialmente nei mainframe, e costituisce la base su cui si sviluppano le codifiche successive (incluso UTF-8).
Clicca qui per saperne di più su ASCII.
ANSI
ANSI, conosciuto anche come Windows-1252, era il set di caratteri predefinito di Windows fino a Windows 95. È un'estensione di ASCII che aggiunge caratteri internazionali. Supportava 256 caratteri utilizzando un byte intero (8 bit).
ANSI era supportato da tutti i browser fin dalla sua introduzione come set di caratteri predefinito di Windows.
ISO-8859-1
ISO-8859-1 divenne la codifica dei caratteri predefinita in HTML 2.0, poiché la maggior parte dei paesi utilizza caratteri diversi da quelli ASCII. È anch'essa un'estensione di ASCII, proprio come ANSI, e aggiunge caratteri internazionali. ISO-8859-1 utilizza anch'essa un byte intero per rappresentare il doppio dei caratteri rispetto ad ASCII.
Clicca qui per saperne di più su ISO-8859-1.
Codifica predefinita in HTML 4
In HTML 4, la codifica veniva dichiarata con un tag <meta> http-equiv. Poiché ISO-8859-1 era il valore predefinito, ecco come si indicava esplicitamente:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1" />Sovrascrivere il charset in HTML 4
Se una pagina HTML 4 necessita di una codifica diversa da quella predefinita ISO-8859-1 — ad esempio ISO-8859-8 per l'ebraico — basta semplicemente modificare il valore charset nello stesso tag <meta>:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-8" />La maggior parte dei processori HTML 4 comprendeva anche UTF-8, il che ha aperto la strada alla sua affermazione come standard in HTML5.
Il metodo HTML5
HTML5 ha sostituito la forma verbosa http-equiv con un attributo breve e dedicato:
<meta charset="UTF-8" />Inserisci questo tag il prima possibile all'interno dell'elemento <head> — idealmente come primo elemento figlio — in modo che il browser legga la codifica prima di analizzare qualsiasi contenuto testuale.
Unicode UTF-8
UTF-8 è la codifica dei caratteri predefinita — e raccomandata — per HTML5.
Poiché i set di caratteri descritti sopra sono ciascuno limitato al massimo a 256 caratteri, il Consorzio Unicode ha sviluppato lo Standard Unicode, un catalogo unico che assegna un numero univoco (chiamato code point) a quasi ogni carattere, segno di punteggiatura e simbolo usato nel mondo — attraverso migliaia di lingue, più emoji e simboli matematici. UTF-8 è il metodo più popolare per codificare quei code point come byte.
Perché UTF-8 è il valore predefinito moderno
Tre proprietà rendono UTF-8 la scelta naturale per il web:
- Copertura universale. Può rappresentare ogni code point Unicode, quindi una singola pagina può mescolare inglese, arabo, cinese ed emoji senza cambiare codifica.
- Compatibile con ASCII. I primi 128 code point sono codificati esattamente con gli stessi byte singoli di ASCII. Qualsiasi file in ASCII puro è già UTF-8 valido, il che significa che decenni di testo e strumenti precedenti continuano a funzionare.
- Efficienza a larghezza variabile. I caratteri comuni occupano solo un byte, mentre quelli meno comuni ne usano due, tre o quattro solo se necessario. I documenti prevalentemente in inglese rimangono compatti, eppure niente viene escluso.
In HTML, l'attributo charset sul tag <meta> specifica la codifica:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>UTF-8 example</title>
</head>
<body>
<p>English, Русский, 中文, العربية, 😀</p>
</body>
</html>Mantieni <meta charset="UTF-8"> come primo elemento nel <head> (entro i primi 1024 byte del documento). Se arriva troppo tardi, il browser potrebbe iniziare ad analizzare il testo con la codifica sbagliata prima di leggere la dichiarazione.
Caratteri multi-byte e il BOM
In UTF-8 un singolo carattere può occupare diversi byte. Ad esempio, il simbolo dell'euro € (code point Unicode U+20AC) è memorizzato come tre byte E2 82 AC, mentre un carattere come A occupa ancora solo un byte. Questo è il significato di "larghezza variabile" in pratica.
Potresti anche incontrare il BOM (Byte Order Mark), una sequenza invisibile facoltativa di byte (EF BB BF per UTF-8) all'inizio di un file che segnala la sua codifica. Un BOM non è necessario per UTF-8 e di solito è meglio ometterlo in HTML, poiché un esplicito <meta charset="UTF-8"> svolge già il compito e un BOM fuori posto può occasionalmente causare anomalie di rendering.
Per inserire simboli specifici senza preoccuparsi di come l'editor salva il file, puoi anche usare entità HTML denominate o numeriche (ad esempio € per €).
Tutti i processori HTML5 supportano UTF-8. Da notare che i processori XML richiedono rigorosamente UTF-8 o UTF-16.