Repository Git
Definizione di repository Git, come inizializzarlo e clonarlo con git init e git clone, salvare modifiche e inviarle al server remoto.
Cos'è un repository Git?
Un repository Git è il contenitore per i file del tuo progetto insieme alla cronologia completa di ogni modifica mai apportata. Ti consente di salvare versioni del codice (commit), spostarti tra quelle versioni e collaborare con altri senza perdere lavoro.
Questa pagina copre l'intero ciclo di vita di un repository: crearlo, apportare e salvare modifiche, collegarlo a un remoto e condividere il lavoro. Ogni passaggio rimanda a un capitolo dedicato dove puoi approfondire.
La directory .git
Tutto ciò che trasforma una cartella in un repository risiede in una singola sottodirectory nascosta chiamata .git nella root del progetto. Contiene la cronologia dei commit, i branch, i tag, la configurazione e l'area di staging. Elimina .git e ti restano solo file semplici — la cronologia delle versioni è persa. Copia .git insieme ai file e avrai copiato l'intero repository.
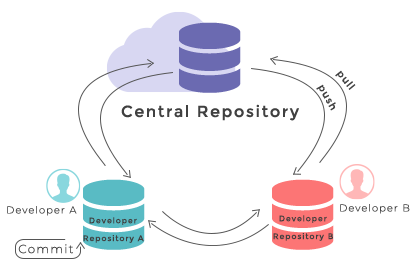
Repository locali e remoti
Git è un sistema di controllo versione distribuito, quindi esistono due tipi di repository con cui lavorerai:
- Un repository locale risiede sulla tua macchina. Puoi eseguirvi commit, creare branch e ispezionarne la cronologia offline — senza bisogno di rete.
- Un repository remoto risiede su un server (ad esempio GitHub o Bitbucket). È la copia condivisa su cui il team esegue push e pull.
Un flusso di lavoro tipico modifica i file localmente, li registra come commit e poi sincronizza quei commit con il remoto.
Git Init per inizializzare un nuovo repository
Usa il comando git init per trasformare una cartella esistente in un repository. Lo esegui una volta sola, quando il progetto non ha ancora il controllo versione.
git init
git initEseguendo questo comando nella cartella del progetto viene creata la sottodirectory nascosta .git e viene stampato qualcosa simile a:
Initialized empty Git repository in /path/of/project/.git/Puoi anche creare il repository in una cartella con il nome desiderato in un unico passaggio passando una directory:
git init directory
git init <directory>Questo crea la cartella (se non esiste) e inizializza un repository Git vuoto al suo interno. Nessun branch punta ancora a un commit; il branch predefinito (di solito main o master, a seconda della versione di Git e della configurazione) inizia a esistere solo dopo il primo commit.
Git Clone per clonare un repository esistente
Se il progetto esiste già su un server remoto, non esegui git init. Usa invece git clone per copiarlo sulla tua macchina. Anche questa è un'operazione che si esegue una volta sola per progetto.
git clone repo url
git clone <repo url>La clonazione scarica la cronologia completa e i file di lavoro e — a differenza di git init — configura automaticamente la sorgente come remoto denominato origin. Ciò significa che puoi eseguire git push e git pull immediatamente, senza configurazioni aggiuntive.
Git Add e Git Commit per salvare le modifiche nel repository
Salvare una modifica è un processo in due fasi in Git. Prima git add sposta le modifiche nell'area di staging (detta anche index) — una zona di attesa dove scegli esattamente cosa andrà nello snapshot successivo. Poi git commit registra quel contenuto preparato come punto permanente nella cronologia. Separare l'operazione ti consente di eseguire il commit solo di alcune modifiche alla volta.
Il flusso seguente crea un file, ne controlla lo stato, lo prepara e lo invia:
- cambia directory in
/path/of/project - crea un nuovo file
GitCommit.txtcon il contenuto "commit example for git repo" - esegui git status per confermare che il nuovo file è non tracciato
- esegui
git add GitCommit.txtper spostarlo nell'area di staging - esegui
git commitcon un messaggio che descrive il lavoro svolto
git add e git commit
cd /path/of/project
echo "commit example for git repo" >> GitCommit.txt
git status
git add GitCommit.txt
git commit -m "added GitCommit.txt to the repo"Esegui git status in qualsiasi momento per vedere quali file sono non tracciati, preparati o modificati. Solo i file che hai esplicitamente aggiunto con git add sono inclusi nel commit successivo. Per escludere completamente dal repository output di build, segreti o dipendenze, elencali in un file .gitignore.
Git Remote Add per connettersi a un repository remoto
Se hai creato il repository con git init, non ha ancora un remoto. Aggiungine uno con il comando git remote. Per convenzione il remoto principale si chiama origin:
git remote add
git remote add origin <remote_repo_url>Verifica che il remoto sia stato registrato prima di eseguire il push:
git remote -vQuesto stampa gli URL di fetch e push per ogni remoto configurato, ad esempio:
origin https://github.com/user/repo.git (fetch)
origin https://github.com/user/repo.git (push)(I repository creati con git clone hanno già origin configurato, quindi puoi saltare questo passaggio.)
Git Push per interagire con il repository
Se hai usato git clone, un repository remoto è già configurato, quindi puoi eseguire git push per inviare le modifiche. Se hai usato git init, devi prima aggiungere un repository remoto (vedi sopra). Puoi usare un servizio Git hosted come GitHub o Bitbucket, creare un repository lì e usare l'URL fornito per connettere il progetto locale.
Dopo aver aggiunto il remoto, puoi fare il push dei branch locali:
git push
git push -u origin mainL'opzione -u (abbreviazione di --set-upstream) fa due cose: invia le modifiche e collega il branch locale a quello remoto. Dopo che il collegamento è stato impostato, puoi eseguire semplicemente git push e git pull senza specificare il remoto o il branch ogni volta.
Git Config per la configurazione e impostazione
Prima del primo commit, Git deve sapere chi sei. Il comando git config imposta opzioni che controllano l'identità dell'utente, le preferenze e il comportamento del repository. Le impostazioni risiedono a tre livelli, ognuno dei quali sovrascrive il precedente più ampio.
Usa il flag --global per impostare opzioni per l'utente corrente. Queste si applicano a ogni repository di tua proprietà, il che è il livello giusto per il tuo nome e indirizzo email:
git repository, git config global user.name
git config --global user.name <name>
git config --global user.email <email>Usa --local (il valore predefinito quando ometti un flag di livello) per impostare un'opzione solo per il repository corrente. Questo è utile quando un progetto ha bisogno di un'identità diversa dal tuo predefinito globale:
git repository, git config local user.email
git config --local user.email <email>Usa --system per impostare la configurazione per ogni utente e repository sulla macchina — ad esempio un editor predefinito condiviso:
git config system editor
git config --system core.editor <editor>Quando la stessa chiave è impostata a più di un livello, local ha la precedenza su global, e global ha la precedenza su system, quindi un valore per repository ha sempre la priorità.
Mettere tutto insieme
Per un progetto completamente nuovo che vuoi condividere, la sequenza completa è:
git init
git config --global user.name "Your Name"
git config --global user.email "[email protected]"
echo "# My Project" >> README.md
git add README.md
git commit -m "Initial commit"
git remote add origin <remote_repo_url>
git push -u origin mainSe invece il progetto esiste già su un remoto, salti git init e git remote add — git clone <repo url> ti fornisce un repository pronto all'uso con un solo comando.
Da qui, approfondisci i singoli comandi: git add e git commit per salvare il lavoro, git status per ispezionarlo, e git push / git pull per la sincronizzazione con il remoto.